Нов изкуствен интелект на OpenAI създава 3D модели по текст за минути
Изкуственият интелект (AI) вече промени много сфери и видимо продължава своята експанзия. Една от следващите му цели е създаването на 3D модели.
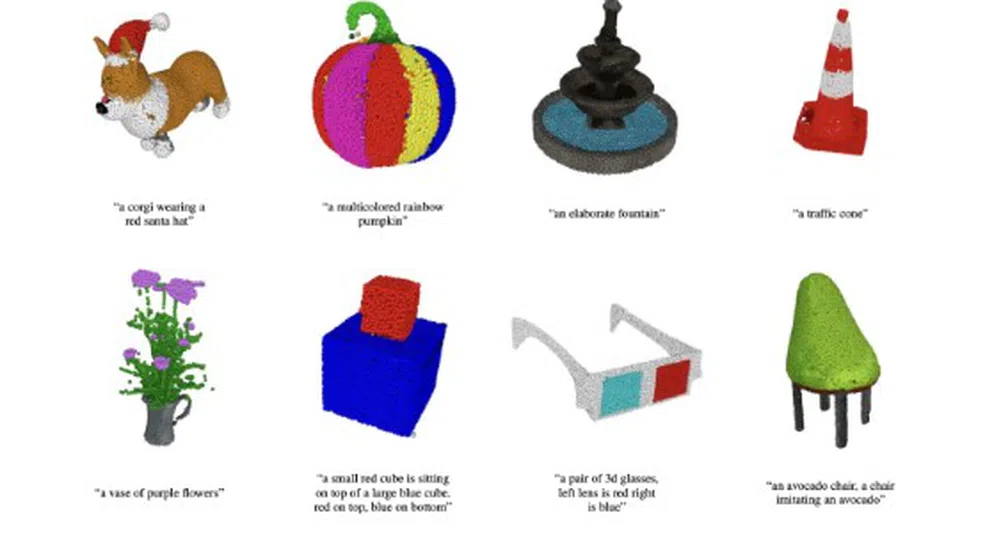
Във вторник, OpenAI, стартъпът за изкуствен интелект, основан от Илон Мъск, който стои зад популярния генератор на текст в изображения DALL-E, обяви пускането на най-новата си платформа POINT-E.
Тя може да създава 3D облаци от точки директно от текстови наставления. И докато съществуващи системи като DreamFusion на Google обикновено изискват няколко часа и няколко графични процесора, за да генерират изображения, Point-E се нуждае само от един графичен процесор и една-две минути, съобщава Engadget.
3D моделирането се използва в различни индустрии и приложения. CGI (Computer-Generated Imagery) ефектите на съвременните филмови блокбъстъри, видеоигрите, VR и AR, мисиите на НАСА за картографиране на лунни кратери, проектите на Google за опазване на културното наследство и визията на Meta за метавселената - всичко това зависи от възможностите за 3D моделиране.
Създаването на фотореалистични 3D изображения обаче все още е процес, изискващ ресурси и време, въпреки работата на NVIDIA за автоматизиране на процеса и мобилното приложение RealityCapture на Epic Game, което позволява на всеки с телефон с iOS да сканира обекти от реалния свят като 3D изображения.
Логичното продължение
През последните години AI системите за преобразуване на текст в изображение като DALL-E 2 и Craiyon на OpenAI, DeepAI, Lensa на Prisma Lab или Stable Diffusion на HuggingFace бързо набраха популярност сред потребителите. Дотолкова, че вече срещу тях се води кампания на много нива от страна на художници по целия свят.
Превръщането на текст в 3D модел е логичното продължение на тези разработки. Point-E, за разлика от подобните системи, "използва голям набор от двойки текст-изображение, което му позволява да следва разнообразни и сложни подсказки“.
„За да създадем 3D обект от текстово задание, първо правим извадка на изображение от базата данни, като използваме модела "текст-изображение", и след това правим извадка на 3D обект, обусловена от извадката на изображението. И двете стъпки могат да се извършат за няколко секунди и не изискват скъпи процедури за оптимизация", обяснява изследователският екип на OpenAI, ръководен от Алекс Никол.
С други думи казано, ако въведете текстово задание "Куче, което яде салам", Point-E първо ще генерира синтетичен изглед на 3D визуализация на споменатото куче, която яде салам. След това генерираното изображение ще премине през поредица от дифузионни модели, за да създаде 3D облак от цветни точки на база на първоначалното изображение - първо ще създаде груб модел на облака от 1024 точки, а след това по-фин от 4096 точки.
Всеки от тези дифузионни модели е бил обучен върху "милиони" 3D обекти, всички преобразувани в стандартизиран формат.
Ако искате да го изпробвате сами, OpenAI публикува кода на проектите с отворен код в платформата Github.
)
СВЪРЗАНИ СТАТИИ



Последни Глобално
виж още&format=webp)
&format=webp)
От „обиколна дипломация“ до лобизъм: Как светът се готви за сценарий „Тръмп 2.0“
 Навсякъде съюзниците на САЩ предприемат стъпки за защита на интересите си, в случай че бившият президент се върне на власт
Навсякъде съюзниците на САЩ предприемат стъпки за защита на интересите си, в случай че бившият президент се върне на власт

Имиграцията като катализатор на икономически растеж – примерът Испания
Тя е допринесла за 64% от новите работни места и за половината от икономическия растеж на страната през 2023 г.
&format=webp)
Великденските добавки и обезщетенията за бременност и раждане ще се изплатят преди празниците
Право на финансова добавка към доходите имат около 534 000 пенсионери у нас
Последни Profit
виж още&format=webp)
За първи път в Европа А1 демонстрира на живо непрекъсваеми 5G и роуминг услуги на границата с Гърция
При завършването през 2025 година 5G SEAGUL ще осигури непрекъсваема 5G и роуминг свързаност по протежение на 450 км, част от които е магистралата между София и Атина
&format=webp)
Без късни удоволствия: Милано иска забрана на пицата и сладоледа след полунощ
Целта на мярката е да запази "спокойствието" в 12 от най-оживените квартали на града
&format=webp)